SIにおける受託開発のプロセス(APアーキテクト目線)
はじめに
受託開発(クライアントがオーナーになるシステムの構築依頼を受ける場合)のプロセスの内、アプリケーション基盤領域のITアーキテクト(APアーキテクト)の仕事内容をまとめたもので、所謂SIerの仕事の一断面です。以降、ITアーキテクト(AP)と記載します。
SIer各社における標準的な開発プロセスや役割分担、クライアント意向など様々な要素の影響を受けるため、SIerにおける標準的な仕事内容を示すものではありません。
プロセス概要
受託開発のプロセスの内、ITアーキテクト(AP)のタスクの概要を示します。ここでは受託開発前の案件化のプロセスも含んでいます。
自社の受託開発においてアジャイル開発を採用するケースが増えてきていますが、まだまだウォーターフォール開発が主軸であり、ウォーターフォール型開発をベースにしたプロセスになっています。

SIer各社における標準的な開発プロセスの定義も様々ですし、プロセスの名称だけで共通の認識を持つのは難しいので、経済産業省が公開している「情報システム・モデル取引・契約書」のモデル契約のフェーズ分割と対応付けておきます。
経済産業省が公開している「情報システム・モデル取引・契約書」はこちら。
www.ipa.go.jp
モデル契約の中で使われているフェーズ分割の定義は以下のイメージです。
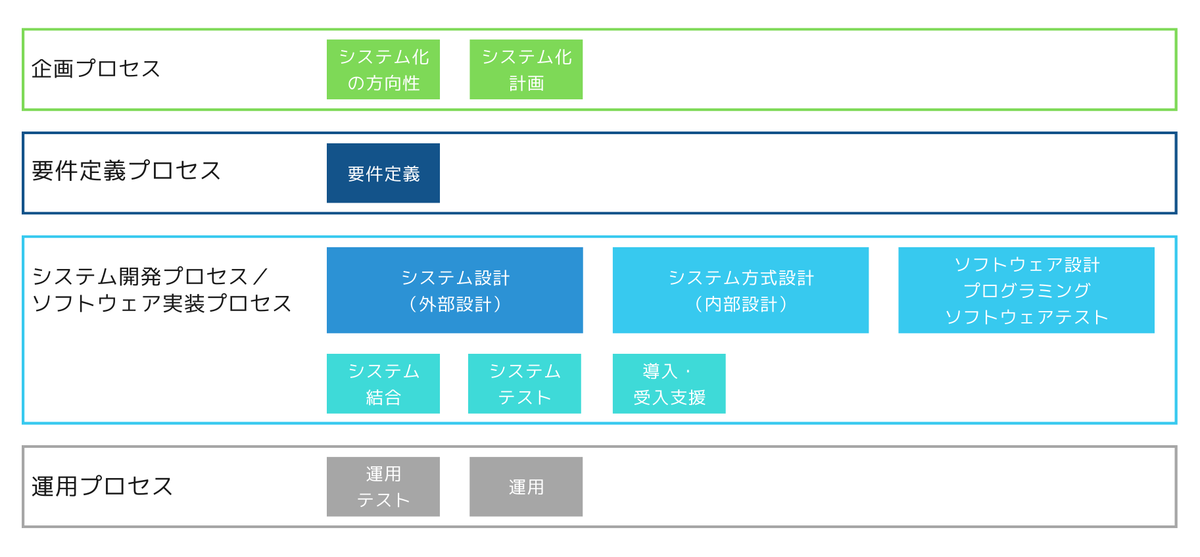
モデル契約の中で使われているフェーズ分割の定義と本記事内のプロセスを対応付けると次のようになります。
| モデル契約 | 本記事内のプロセスとの対応 |
|---|---|
| 企画プロセス | 案件化/提案 |
| 要件定義プロセス | 要件定義 |
| システム設計(外部設計) | 仕様策定 |
| システム方式設計(内部設計) ソフトウェア設計 プログラミング ソフトウェアテスト |
実装 |
| システム結合 システムテスト 導入・受入支援 |
テスト |
| 運用プロセス | - |
境界が曖昧な設計と実装について補足します。私が参画している開発ではクライアントから開発プロセスおよび契約形態を指定されているケースを除き、規模に依らず内部設計や詳細設計と呼ばれる設計を単独で実施するケースは直近10年では無くなり、設計と実装を並行させたり設計をリバースエンジニアリングで出力するケースに置き換わっていますので、実装とだけ表現しています。
- 仕様策定
どのようなユーザーインターフェイスにするかなど、システムの振る舞いを決めるプロセスです。システムの振る舞い=外部仕様と表現します。外部仕様には、外部接続のインターフェイス(公開API含む)の定義も含みます。 - 実装
契約上、基本的には内部(詳細)設計とプログラミング(実装)はまとまった請負契約になるので、納品対象に設計書が含まれていてもソースコードと併せて納品する形となり、設計ドキュメントの作成とプログラミングの順序は任意とすることが出来ます。なので、 設計と実装を並行させたり設計をリバースエンジニアリングで出力するといったことが可能になっています。
Unit Testingはここに含みます。
内部設計や詳細設計と呼ばれる設計が単独で実施されなくなってきたのは自社で起こっていることなので一般論ではありませんが、個人的に以下のような理由によるものと考えています。
- フレームワークやライブラリの充実によって、単純なCRUD処理の実装に必要なコードが少なくなった
- フレームワークによって構造が決められ、細かい分割を除いて構造設計が不要になった
- 様々な失敗からアーキテクチャ策定および方式設計が重視されるようになった結果、基本的な処理パターンについては量産できるようにプロセス化された
- 基本的な処理パターンに収まらないものは実装してみないと不明な点が多く、机上で設計の完成を先行させることが非効率になった
体制/役割
比較的規模の大きな開発における体制の例です。

ITアーキテクトは以下のように役割分担されることが多いです。
- ITアーキテクト(ドメイン)
ドメイン知識を持ち、業務分析や機能要件整理、外部仕様策定をリードしつつ、それらの整合性を保ちます。また、Featureチームのリードも担います。 - ITアーキテクト(AP)
非機能要件整理、アプリケーション方式設計、アプリケーション基盤構築、設計/実装標準化を担います。 - ITアーキテクト(インフラ)
非機能要件整理、インフラストラクチャの設計と構築を担います。
ITアーキテクトの役割は分かれますがそれぞれが密接に関わるタスクが多く存在し、それぞれの意思決定によって他に影響を与える場合は合意形成を行います。本来は役割がまとまった方が調整が少なく、役割の間に落ちるボールも無くなりますが、特に規模の大きな開発ではタスクの物量やスキルセットの問題でこのように分担されることが多くなっています。
仕事内容
案件化/提案と要件定義以降に分け、要件定義以降は開発の流れとして紹介します。
案件化/提案
案件化においては、クライアントがシステム化/再構築の企画を進めるにあたって、採用候補に挙がっている技術要素についての勉強会や適用事例の紹介など、クライアント内で合意形成を図ったり、企画化するための活動を支援することが中心になっています。直近のテーマに挙がった技術要素は次の通りです。
- マイクロサービスアーキテクチャ
- OAuth/OIDC
提案においては、クライアントのヒアリングやシステムの構成案検討とその根拠を示す資料作り、プレゼン時の技術回答などを主に担当しています。
開発の流れ
ITアーキテクト(AP)目線の開発の流れの例です。
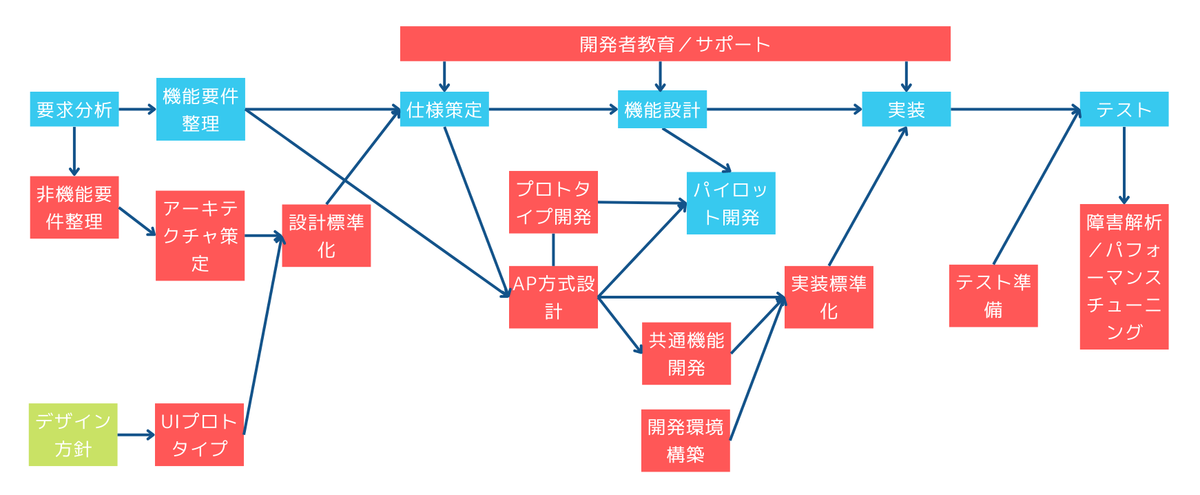
タスク詳細
非機能要件整理
クライアントへのヒアリングを元に、主にITアーキテクト(インフラ)と共同で実施しています。
整理する内容を以下に例示します。
非機能要求グレードより
- 可用性
- 性能・拡張性
- 運用・保守性
- 移行性
- セキュリティ
- システム環境・エコロジー
その他
- ユーザービリティ
- アクセシビリティ
ITアーキテクト(AP)は主に以下の整理に関わっています。
- 性能(処理パターン抽出)
- セキュリティ(リスク分析、セキュアコーディング、データ秘匿化、認証/認可)
- 運用・保守性(ログ)
- ユーザービリティ
- アクセシビリティ
アーキテクチャ策定
主に以下のようなタスクを実施しています。
- システム構成検討(提案時のシステム構成案の精緻化)
- 技術選定(製品、ツール、ライブラリ)
提案時に開発言語やフレームワークはほぼ決定していますが、稀に見直しを行うこともあります。基本的にはそれ以外の製品やツール(CI/CD、エディタ、テスト)や主要なライブラリの選定を行います。製品選定は例えばOCRや帳票製品などがありますが、実績が十分でない製品の選定には実現可能性の検証を伴います。 - アーキテクチャパターン整理
処理方式(システム間連携、オンライン、バッチ、非同期)のパターン洗い出し、処理パターンごとのアーキテクチャ策定。
実績が十分でないものについては、技術検証を行いながら策定していきます。
UIプロトタイプ
デザイン方針を受けて、メニューなどのフレームやフォームなどの個別要素、登録やアップロードの主要な処理パターンから、一括編集など複雑だったり認識ずれが起きそうなリスクの高い要素などをピックアップして行います。これによって、クライアントとおおよそどのようなUIの作りにするか認識を合わせます。UIプロトタイプが無くてもクライアントと認識ずれが起きなさそうな場合は省略されることがあります。実施されるケースは例えば、業務用クライアントアプリケーションをWeb化する案件では、現行システムと新システムの違いが大きいために認識ずれが起きやすく、UIプロトタイプが実施される、といった感じです。
UIプロトタイプの入力となるデザイン方針はUI/UX担当が主導しますが、UIコンポーネントライブラリの選定などの技術選定はITアーキテクト(AP)が担当している都合、実装し易い形になるように、調整を行っています。
設計標準化
- UI設計ガイドライン策定
UIプロトタイプに解説を付けるなどして、UI設計のガイドラインを策定します。これによってデザインガイドラインでは示されない、例えばイベントの発生タイミングなどのUIの振る舞いを機能設計の担当共有しつつ、設計上の規約を示します。 - 設計要素の洗い出し、設計ドキュメント記述ガイドライン策定
標準的な設計要素はありますが、システム特性を考慮してテーラリングを行います。 - 標準化プロセス定義
属性の洗い出しとその定義など、設計情報を集約して整合性をとるためのプロセスを整備します。
そのほかに例えば、監査機能などを共通機能で実現する場合、監査対象のイベントや監査情報として残すデータに関する情報、マスキング対象などを個別の機能設計から集約する方法とそのプロセスを整備します。
AP方式設計
以下のような内容を設計しています。
プロトタイプ開発と併せて技術検証を行いながら設計を進めることが多いです。
- 構造定義(論理構造/物理構造/配置構造)
レイヤー分割/役割定義、ディレクトリ構造、URL構造、モジュール配置 - セキュリティ
- 認証/認可
- 監査
- データ保護
- Webセキュリティ対策
- トランザクション
- 同時実行制御
- リトライ(ポリシー、方式)
- 文字の扱い(文字コード、許可/拒否する文字セット、照合順序)
- 状態管理(サーバー、クライアント)
- データ削除(論理削除/物理削除)
- 例外(業務例外とシステム例外の扱い)
- ログ
- 閉塞
- システム間連携
- オンライン処理(正常系/異常系、アップロード/ダウンロード、一括編集)
- バッチ処理(正常系/異常系)
- 非同期処理(正常系/異常系、通知)
- 帳票出力
- システム間連携
共通機能開発
主に非機能領域の共通機能の開発を担います。機能領域のものは主にITアーキテクト(ドメイン)が開発を担います。
非機能領域の共通機能は例えば、認証/認可やログ、トランザクション管理などで、その内フレームワークやライブラリで不足する機能を実装します。
- バックエンドの共通機能の例
Authn/z Filter/MiddlewareやCustom Annotation、その他DI/Interceptorなどを使った機能 - フロントエンドの共通機能の例
AuthGuardやCustom Validation、その他Hook/Interceptorなどを使った機能
プロトタイプ開発
AP方式設計の結果をプロトタイプ開発で検証します。AP方式設計において必要な技術検証の多くはこのプロトタイプ開発と併せて実施しています。
開発環境構築
開発者のローカル環境および共有の開発/テスト環境の構築を行います。
- ローカル環境向け
エディタやLinter/Formatterなどの設定やビルドスクリプト、テストスクリプトなどを整備 - 共有の開発/テスト環境向け
環境変数や設定ファイル、キーストアなどの準備やCI/CDパイプラインの整備
実装標準化
開発者教育/サポート
テスト準備
開発を担当した共通機能および非機能テストのテストシナリオ/テストケース/テストデータ作成、環境準備(環境変数、設定ファイル)などを行います。
場合によってはテストプログラムの作成やテストツールのシナリオ作成なども実施します。
障害解析/パフォーマンスチューニング
開発を担当した共通機能の障害の解析およびパフォーマンスチューニングを実施するほか、機能面でITアーキテクト(ドメイン)/Featureチームで解決できない問題を担当します。後者は基本的には解析結果や改善案を提示して後はITアーキテクト(ドメイン)/Featureチームに任せることが多いです。
おわりに
SIerのコア事業である受託開発のプロセスの内、APアーキテクトとして仕事してきた内容を棚卸ししてみました。
繰り返しになりますが、SIer各社における標準的な開発プロセスや役割分担、クライアント意向など様々な要素の影響を受けるため、SIerにおける標準的な仕事内容を示すものではありません。
障害解析の進め方
概要
技術部門に異動してから10年以上にわたって実践してきた、他部門から依頼された障害解析における思考およびプロセスを残すものです。
初見のアプリケーションの障害解析が中心だったり、構成に利用したことのないインフラや製品などが含まれることも普通にあるので冗長な部分も多いですが、汎用的な内容になっていると思います。
障害解析の基本的な流れ
これまで実践してきた障害解析の基本的な作業の流れを以下にまとめました。
最初に障害の事象に関して、情報を集め状況を整理するところから始めます。集めた情報を元に関連箇所の絞り込みと障害原因のおおまかな分類を行い、原因分類に応じた解析を行います。
ログメッセージで原因がすぐに特定されるようなわかりやすい事象や経験により即座に原因を類推出来るケースでは、この流れで実施する作業の多くはスキップします。
事象の整理
- 資料の採取
- システム構成の確認
- 環境依存性の確認
- 発生前後の変更の確認
- 事実の整理
- 時系列の整理
- 再現性の確認
解析
- 関連箇所の絞り込み
- 原因の分類
- 解析
各作業におけるポイント
事象の整理
必要な情報を収集して、発生している事象を正確に整理することは非常に重要です。
過去に解析した実績では、情報不足や誤った情報によって解析が長期化したケースは多く、逆に情報が十分であれば、過去の知見により即時に発生原因を特定出来たケースもありました。
資料の採取
ログ(アプリケーションログ、サーバーログ、イベントログ、パフォーマンスログなど)、ダンプファイル、ネットワークキャプチャなど、解析に必要な資料を採取します。
必要な情報が残っていないと解析不能に陥る可能性が非常に高くなるので、削除される可能性のある資料には気を付ける必要があります。特に最大サイズやローテーションなどが設定され、バックアップを行っていない資料に気を付けましょう。また、解析不能になってしまった場合、これらの設定の見直しを行いましょう。
システム構成の確認
明らかなアプリケーションのバグなど障害の原因が特定できているケースを除き、システム構成から関連する要素を整理しておきます。
システム構成を確認しながら、障害に関係ありそうな箇所と関係無さそうな箇所の色分けを行うことで、調査の範囲を絞り込みます。
過去の経験から、ネットワークが原因となっていたケースでは、システム構成を確認した段階で疑わしい箇所は絞り込むことが出来ていました。疑わしい箇所の代表として、TLS(SSL) アクセラレータやロードバランサーが挙げられます。最近ではマネージドサービス固有の制限やサービスダウンなどのケースも増えてきました。
環境依存性の確認
特定の環境でしか発生しない場合は環境差異に着目します。着目するポイントは、稼働環境、ハードウェアやネットワーク、ソフトウェア環境の差異、リリースしているアプリケーションの差異です。
過去の解析で多かった差異は、ロードバランサーの有無、インストールソフトウェアバージョンの違い、端末の機種や OS、設定の違いなどです。
発生前後の変更の確認
直近のインフラまたはアプリケーションの変更に着目することで、原因に当たりを付けることが出来ます。
アプリケーションの変更があったケースでは、ソースコードの差分に着目し、事象との関連性を確認します。
インフラに変更があったケースでは、変更が及ぼす影響と事象との関連性を確認し、原因を類推します。
事実の整理
情報を整理する際に、事実と不確かな情報を分けて整理しておくことが重要です。
疑わしい箇所を探していく段階では不確かな情報でも有用ですが、事実とそうでないかが整理されていないと、先入観により原因箇所に目を向けるまでに時間がかかってしまうケースや再確認により更に時間がかかってしまうケースがあります。
時系列の整理
ログや環境変更、リリース、オペレーションなどログとログに残らないようなイベントも含めて、関連する情報を時系列に整理することで、規則性など解決の糸口が見えてくることがあります。
また、特定のタイミングによって発生する問題や複数の処理が関連して発生する問題を解決するためには時間軸を正確に把握しておく必要があります。
時系列が正しく整理できておらずに認識を誤ると、やはり先入観により原因箇所に目を向けるまでに時間がかかってしまうケースがあります。
再現性の確認
原因にもよりますが、一度きりの障害発生では資料が採取出来ないこともよくあります。その場合は、再現テストが重要になります。繰り返し事象を再現させることが出来る場合、ほぼ間違いなく原因特定に至ります。
事象整理の流れについてまとめてきましたが、事象整理した段階で過去の知見により即時に発生原因を特定できるケースを除き、再現テストが解決への一番の近道になります。
解析
事象が整理できたら、それらの情報を使って関連箇所を絞り込み、障害を大まかに分類し、解析を行っていきます。
関連箇所の絞り込み
システム構成上の関連要素、環境依存性、発生前後の変更などから関連個所を絞り込んでいきます。
再現性がある場合は、例えばユースケースから関連する処理が導き出せていることでしょう。他にログから類似事象の情報が見つかったり、リソース状況から特異点が見つかったりなど整理した内容を手掛かりに、関連個所を絞り込んでいきます。
ここで先入観を持ちすぎず、別の可能性も想定しておくことが重要です。
原因の分類
関連箇所の絞り込みを行っていくと、関連する処理や類似事象の情報、リソース状況の特異点などから、おおよその原因に当たりをつけることができます。
過去の経験に基づく分類になりますが、代表的な原因の分類をアプリケーションがクラッシュするケースとハングするケースに分けて以下に示します。
| 原因分類 | クラッシュ | ハング |
|---|---|---|
| メモリー使用量の増大 | OutOfMemoryException の発生やネイティブメモリの割り当て時に実行時エラーが発生。主な原因はメモリーリークや大量メモリーを確保するロジック、負荷集中などによるメモリーの逼迫。 | 応答停止やスローダウンが発生。メモリー使用量が OS やプロセスの上限まで上昇する。主な原因はメモリーリークや大量メモリーを確保するロジック、負荷集中などによるメモリーの逼迫。 |
| I/O | IOException やタイムアウト系のエラーが発生する。主な原因は I/O の競合。 | 応答停止やスローダウンが発生。事象発生時には、Disk Queue Length 値の増加が見られる。主な原因は特定ファイルへのアクセス集中、アンチウィルスソフトウェアなどによる想定外の負荷発生など。 |
| ネットワーク | 想定外の実行時エラーが発生する可能性が高い。例:二重送信、順序不正主な原因はネットワーク機器や Web サーバーの不具合や設定誤り、クライアントの強制切断など。 | スローダウンが発生。主な原因はバーストトラフィック |
| バグ | 想定外の実行時エラーが発生。アプリケーションのバグから OS やミドルウェア、フレームワークのバグなど、原因は多岐にわたる。例:access violation の発生、OS リソース枯渇(ハンドルの割り当てエラー)など | 応答停止やスローダウンが発生。原因は多岐にわたる。例:スレッド間デッドロック |
解析
ここから個別の解析になっていきますが、原因分類ごとにどのような思考とプロセスで解析を行ったのかをまとめておきます。
メモリー使用量の増大
調査方法概要
以下の流れで調査します。
- 原因の切り分け
- メモリー使用量を増加させる箇所の特定
原因の切り分け
メモリー使用量が増大する原因は、大きく分けて以下の 2 つに分類されます。
メモリー使用量を増加させる箇所の特定
メモリー使用量が増加した状態でメモリーの状態を確認して、オブジェクト数が多いもの、サイズが大きいオブジェクトを探す形が基本です。
調査方法詳細
必要な資料
事象の発生に備えておく資料としては以下があります。
- パフォーマンスモニタのログ(メモリー関連)
- ダンプ
パフォーマンスモニターは、メモリー増加の傾向を見るために使用するので、日常的に取得しておきましょう。
ダンプはメモリー増加の時系列に沿って複数取得しておくと、解析時に差分比較により原因となる箇所を特定できる可能性があります。
原因の切り分け
パフォーマンスモニタのログから、次のようにメモリーリークか一時的なメモリー使用量の増加なのかを切り分けます。
- メモリー使用量の傾向を確認する。
- 使用量は急激に増加するか、漸増するか
- 使用量が減少するタイミングがあるか
急激に増加してもその後減少するのであれば、一時的な負荷の可能性が高いです。一方、急激あるいは少しずつ増えたメモリーの使用量が、時間がたっても減らない場合は、メモリーリークの可能性があります。
メモリー使用量を増加させる箇所の特定
メモリーの状態の確認
デバッグ、デバッガーのアタッチ、プロファイラーの使用、ダンプなどからメモリの状態を調べます。オブジェクトの数とサイズでソートし、怪しいオブジェクトをピックアップします。
複数のタイミングで確認できる場合は、差分を見ることで増加しているオブジェクトが容易に特定できます。参照関係の確認
増加しているオブジェクトの参照関係をたどり、それを保持しているオブジェクトを特定していきます。処理の特定
参照関係の確認を行っている時に参照関係にアプリケーションで実装しているオブジェクト(ユーザーオブジェクト)を見つけられれば、処理の特定は簡単です。ソースコード上でユーザーオブジェクトを扱っている箇所を確認していきます。
ユーザーオブジェクトが出てこない場合、フレームワークやライブラリなどに調査が及ぶことになります。
多く観測された原因
- イベントハンドラーの解除漏れ
- ロジック誤りによるオブジェクトの蓄積
- static領域のオブジェクト残存
I/O
調査方法概要
以下の流れで調査します。
- 原因の切り分け
- I/O の集中や競合を発生させているプロセス、処理の特定
原因の切り分け
クラッシュの場合はログにファイル名が出るなど、I/O の問題とすぐに断定出来るケースが多いので、ここでは解説を省略します。
ハングの場合は少しややこしく、ビジー状態の場合はパフォーマンスモニタのログで当たりを付けられるため、I/O を原因として想定し易いですが、フリーズ状態の場合は最初から I/O を原因として想定することは難しいことが多く、後述の「バグ」の解析手順の結果、I/O を原因と想定した解析を行うパターンが多いです。
ハングの場合で I/O を疑って調査を行う場合、ネットワークが原因になっていることもあるため、ディスクの問題なのかネットワークの問題なのかを切り分ける必要があります。
I/O が問題となる場合の主な原因としては、以下が挙げられます。
- I/O の集中
- 同じリソースに対してアクセスが競合
I/O の集中や競合を発生させているプロセス、処理の特定
I/O の集中による問題は、要求に対してスペックが不足している場合以外に、そもそも想定していなかった I/O 要求が発生したケースが過去の解析では多くありました。
想定外の I/O要求を発生させた原因の大半はアンチウィルスソフトウェアによるもので、これについては知識を持っておけば、原因の特定に至るまでスムーズに解析することが出来ます。
また、事前に除外などの対策も忘れずに検討しておきましょう。
調査方法詳細
必要な資料
主に採取・使用する資料を示します。
- パフォーマンスモニターのログ(ディスク関連)
ネットワークストレージ、ファイルサーバーの場合、ネットワークが起因しているケースがあります。その場合、ネットワーク関連のパフォーマンスモニターのログも合わせて確認する必要がありますが、詳細は割愛します。 - ダンプ
- 監査ログ
- プロファイラーのログ
よく使用するツール
- パフォーマンスモニター
ディスク関連のパフォーマンスモニターのログの解析に使います。 - ディスクアクセス監査ツール
ファイルアクセスの統計情報の確認やプロセスの特定、ファイルアクセスの流れの確認に使用します。処理を特定する場合は、デバッガーやプロファイラーを使用します。 - デバッガー
主にダンプの解析に使用し、ファイルハンドラを保持している処理の特定などの解析を行います。フリーズの場合、待機中のスレッドとその処理を確認します。 - プロファイラー
ファイルハンドラを保持しているプロセスの特定や、ファイルアクセスの処理の流れの確認に使用します。
原因の切り分け
- I/O 集中が疑われる場合、事象発生時のアクセス数から想定外のアクセスが発生していないかどうかを確認します。
- アクセス数が許容範囲内である場合、ディスクアクセスの待ち状態を確認します。
特定のファイルにアクセスが集中しておらず、待ちが発生している場合はスペック不足の可能性があります。
I/O の集中や競合を発生させているプロセス、処理の特定
アクセス元のプロセスの確認
アクセス元のプロセスを特定します。この時点で、アンチウィルスソフトウェアが原因であった場合は特定に至ります。
アプリケーションのプロセスがリストアップされた場合、処理の特定を行っていきます。
ファイルロックにより競合が発生している場合は、監査ログから特定するのは難しいケースもあり、その場合は再現テストが必要になります。処理の特定
アプリケーションのプロセスが原因であった場合、競合が発生していたファイルにアクセスしている処理をソースコード上で特定します。この場合、マルチプロセスやマルチスレッドの考慮が出来ていないことが想定されます。
ソースコード上の特定に時間がかかる場合や他プロセスによるファイルロックが疑われる場合は、再現手順が確立しているのであれば、以下のような手法での解析も可能です。
多く観測された原因
- アンチウィルスソフト
- プロセス/スレッド間の排他制御ロジックの不備
- エディタなどの外部プロセスによるファイルロック
ネットワーク
調査方法概要
ネットワークを原因として想定し、調査に至るまでのパターンについては、大きくクラッシュとビジー状態のハングのパターンがあります。
ビジー状態のハングについては、パフォーマンスモニターのログで当たりを付けられるため、わかりやすいパターンと言えます。
クラッシュの場合は発生する事象が特殊なケースが多く、ワンタイムトークンのチェックエラーや処理順序不正エラーなどで表面化することがあります。これらの事象を引き起こす原因は、二重送信、遅延による前後関係の逆転などであり、そういった原因を想定して調査を進める必要があります。
バーストトラフィックにより、ビジー状態のハングが発生しているケースについてはわかり易いので、ここでは以下のクラッシュのパターンについて解説します。
- 想定外の通信の発生
想定外の通信の発生
表面化する事象が特殊なケースが多いため、初期の段階ではネットワークが原因と想定することが出来ないケースがあります。
そのため、ここではこれまでに遭遇した代表的な事例を列挙します。
調査方法詳細
必要な資料
主に解析に使う資料としては以下があります。
- パフォーマンスモニタのログ(ネットワーク関連)
- 通信ログ(HTTPリクエスト/レスポンスのログ)
- パケットキャプチャ
情報を採取する場合、通信の片側のみからでは解析が十分に出来ない可能性があることに注意し、可能な限り関連する機器間の通信ログを採取するようにします。
例えば、クライアントから中継器までの間に通信異常があった場合、サーバー側のログではそれが判断出来ません。
よく使用するツール
- パフォーマンスモニター
ネットワーク関連のパフォーマンスモニターのログの解析に使います。 - パケットキャプチャー
通信内容の確認に使います。
想定外の通信の発生
通信結果の確認
ログを参照し、通信時間や終了ステータスを把握します。
通信ログのタイムスタンプは通信の終了時に記録されることを念頭において、ログの順序と時系列の間に誤った認識を持たないように注意します。
ブラウザーを閉じるなどクライアントとの通信に異常があった場合には、ログの出力内容が通常とは異なり、これが手掛かりになる可能性があります。通信ログ、キャプチャーから通信内容の確認
時系列に沿って通信内容を追いかけ、プロトコルやアプリケーションのフローと照らし合わせて特異点、不整合を見つけていきます。
リセットパケットや再送などが発生しているケースがあるので、イレギュラーな通信が発生していないかという観点で見ることで手掛かりを見つけられる可能性があります。通信ログとキャプチャーから想定外の通信を発生させている箇所を特定
基本的に送信元 IP を見て送信元を判断しますが、ロードバランサーやTLS(SSL)アクセラレータ、プロキシサーバーなどの中継機器の存在を認識しておく必要があります。
また、X-Forwarded-Forなどに送信元IPアドレスが設定されるケースも抑えておく必要があります。
多く観測された原因
バグ
障害の原因となるバグには多様なものがあり、調査方法もバグに合わせて千差万別です。 そのため、ここでは解析が困難なユーザーコード外の OS やミドルウェア、フレームワークに存在するバグに起因した障害の一般的な調査方法をまとめます。 また、ここまでに解説した、メモリー使用量の増大、I/O、ネットワークの 3 つに関しても、OSやフレームワーク等のバグが根本的な原因となって引き起こされるケースが存在します。
調査方法
原因として OS やミドルウェア、フレームワーク等のバグを疑う場合は、以下の 2 つの方面から原因の特定を目指します。
- 原因となる箇所の特定
- 類似事例の調査
原因となる箇所の特定
バグの関与を疑う場合は、事象が発生する最小セットのプログラムで再現させることを目指し、再現性を取った上でプログラムの問題とは関係ない部分を取り外していき、発生個所や条件を絞りこんでいくとよいでしょう。
最小セットのプログラムで再現させた後、原因となる箇所の特定を行います。
類似事例の調査
多様なバグの中から障害の原因となるものを見つけ出すのに有効な手段としては、机上にて類似事例を調査するという方法があります。
OSS のリポジトリやベンダーが公開している Knowledge Base(KB)、Stack Overflowといった開発者が集まるコミュニティサイトに有力な情報が存在する可能性があります。発生状況やログなどに出力される例外のメッセージ等を頼りに、情報を探します。Googleなどの検索エンジンで広く情報を探すのも有効です。
必要な資料
主に解析に使う資料としては以下があります。
これらの資料から、最小セット作成を目指すための発生条件の特定や、机上調査対象とする例外メッセージの取得を行います。
調査が長期化/追及不能になりがちなケース
これまで見てきたバグによる障害の中で、もっとも厄介な種類のものが access violation や buffer overrun といったメモリアクセス違反よるクラッシュに関するものです。
buffer overrun 等によりメモリーの状態が破壊された場合、access violation が発生した段階ではメモリーを破壊したのがいずれの処理か特定するのが難しく、メモリアクセス違反に関する障害は再現性が取れずに長期化/追及不能となるケースがありました。
このようなケースでは、再現方法の確立が解決への一番の近道となる可能性が高いです。
おわりに
こうしてまとめてみると、オンプレ時代からの名残が多く残っているなと感じますが、障害解析の思考およびプロセスとしては今も無意識で実践していることが多いなと思いました。
VSCode Dev Containers(旧Remote Containers)を使った開発環境構築
概要
ソフトウェアやライブラリなどのアップデートを検証する際の使い捨て環境、開発環境構築の自動化などにVisual Studio CodeのDev Containersが便利です。
Dev Containersを利用すれば、開発環境で手軽にDockerコンテナーを扱うことができます。コンテナーの作成やコンテナに配置したソースコードをVS Codeで編集、アプリケーションの実行といったことが簡単に出来るようになります。Dev Containersを利用する際の開発環境のイメージとその詳細は以下を参照してください。
 Developing inside a Container using Visual Studio Code Remote Development
Developing inside a Container using Visual Studio Code Remote Development
Visual Studio CodeのDev Containersを使って、開発環境を構築していきたいと思います。 今回はWSL2がセットアップ済みのWindowsでやっていきます。
今回の環境
- Visual Studio Code: 1.74.2
- Visual Studio Code拡張機能
- Dev Containers: v0.266.1
- WSL: v0.72.0
>wsl --version WSL バージョン: 1.0.3.0 カーネル バージョン: 5.15.79.1 WSLg バージョン: 1.0.47 MSRDC バージョン: 1.2.3575 Direct3D バージョン: 1.606.4 DXCore バージョン: 10.0.25131.1002-220531-1700.rs-onecore-base2-hyp Windowsバージョン: 10.0.22621.963
コンテナ作成手順
セットアップ方法や使い方は基本的に公式ドキュメントを見れば大丈夫です。 code.visualstudio.com
バージョンによって変わる可能性が高いので、ここでは簡単に紹介します。
- Dockerファイルなどを格納するディレクトリを作成します。
- 上記ディレクトリをルートにしてVS Codeを開きます。
- WSLで開き直します。

- ここからDev Containersの環境を作っていきます。まずは
Add Dev Container Configuration Filesを実行します。
- 今回は複数のコンテナを作成する想定で
Docker outside of Docker Compose devcontainersを選択します。
 Dev ContainersでDockerコンテナからDockerを使う構成は、
Dev ContainersでDockerコンテナからDockerを使う構成は、Docker in Docker(dind)とDocker outside of Docker(DooD)の二種類があります。 dindとDooDの違いについてはこのあたりを参照してください。 qiita.com dindとDooDの使い分けについてはこちらも参考にしてください。 jpetazzo.github.io - 適当に選択を進めていきます。



- Dev Containersで使う設定ファイル(devcontainer.json)とdocker-compose.yml、Dockerfileが生成されました。

ここでは、わかりやすくVS Codeから見える位置にソースコードを配置するのに、バインドマウントの設定を追加します。ディレクトリを追加し、その位置をdocker-compose.ymlの
volumesで指定します。

volumes: # Forwards the local Docker socket to the container. - /var/run/docker.sock:/var/run/docker-host.sock # Update this to wherever you want VS Code to mount the folder of your project - ../..:/workspaces:cached - type: bind source: ../my-volume # ホスト側のYAMLからの相対パス target: /workspaces/node-app # コンテナ側の絶対パスNode.jsの開発環境を試したいので、Dockerfikeを次のように編集します。
FROM node:18Node.jsの公式イメージのユーザーに合わせて、コンテナのユーザーをdevcontainer.jsonで指定しておきます。
"remoteUser": "node"準備が出来たので、
Dev Containers: Reopen in Containerでコンテナを起動します。
- コンテナの作成が始まります。
動作確認
コンテナが起動してコンテナに接続されたら、Node.jsの環境が正しく構築されたか確認しておきます。
node@99cf54e2f43d:/workspaces/node-app$ node -v v18.12.1ソースコードの参照とアプリケーションの実行を試したいので、create-react-appを実行します。
node@99cf54e2f43d:/workspaces/node-app$ npx create-react-app my-app Need to install the following packages: create-react-app@5.0.1 Ok to proceed? (y)Reactアプリケーションが作成されたことを確認します。
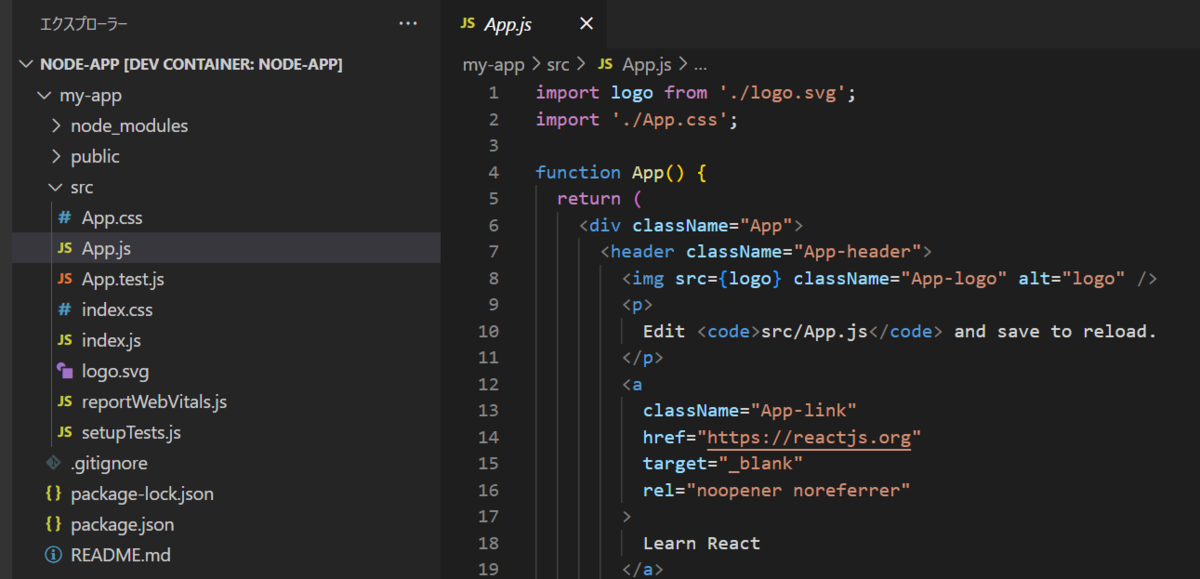
アプリケーションの実行も試してみます。
node@99cf54e2f43d:/workspaces/node-app$ cd my-app node@99cf54e2f43d:/workspaces/node-app/my-app$ npm startブラウザが起動してアプリケーションが表示されました。

- ホスト側でもソースコードを開いてみます。

おわりに
Gitなど大分省略しましたが、ここまででDev Containersを使った開発環境の構築を通して、コンテナーの作成やコンテナに配置したソースコードをVS Codeで編集、アプリケーションの実行というところまで確認出来ました。
Docker Comose バインドマウントと相対パスの名前付きボリューム
概要
Dockerボリュームのバインドマウントとdriver optionの相対パス指定について記載します。
Visual Studio Code Dev Containersを使って開発環境を作る時に個人的に必要になった情報をまとめています。
バインドマウント
バインドマウントはDockerコンテナ内で扱うファイルをホスト側に保存する仕組みで、Dockerコンテナ内で扱うファイルをホスト側に保存する仕組みは他にボリュームがあります。
 バインド マウント(bind mount) の使用 — Docker-docs-ja 20.10 ドキュメント
バインド マウント(bind mount) の使用 — Docker-docs-ja 20.10 ドキュメント
バインドマウントはホスト側のファイルをコンテナにマウントし、マウントしているファイルがホスト側の管理になるのが特徴です。
ソースコードをホスト側で編集して、コンテナ側でそのソースコードをビルドして実行、という形に都合が良かったりします。
バインドマウントの定義例
services: app: volumes: - type: bind source: ./app/volume # ホスト側の docker-compose.yml からの相対パス target: /workspaces/app # コンテナ側の絶対パス
この場合は識別子を付けて管理することはできず、docker volume lsを実行すると、
可読性の無いIDが表示されることになります。
driver optionの相対パス
driver optionを使用すると、識別子に任意の名前を付け、かつバインドマウントにすることができます。
driver optionを使った定義例
services: app: volumes: - app-volume-id:/workspaces/app volumes: app-volume-id: driver: local driver_opts: type: none o: bind device: '${PWD}/app/volume'
ここで相対パスを指定したい場合、カレントディレクトリを表す${PWD}を使います。
Compose does not mount volume if I use relative path · Issue #9191 · docker/compose · GitHub
Dev Containers
Dev Containersで環境を作っている場合、次のバインドマウントの定義によってホスト側に配置したソースコードをマウントした後、VS Code Serverを通してソースコードにアクセスすることができるようになります。
services: app: volumes: - type: bind source: ./app/volume # ホスト側の docker-compose.yml からの相対パス target: /workspaces/app # コンテナ側の絶対パス
さらに、Dev Containersに固有のボリューム構造があり、自動的に識別子が付与され、docker volume lsを実行した時に可読性の無いIDが表示されることもありません。
Developing inside a Container using Visual Studio Code Remote Development
Dev Containers、積極的に使っていこう。
PiniaのactionからVue Routerを使ってルーティング
概要
Pinia のドキュメントに記載の通り、ストアインスタンスのプロパティに Vue Router のインスタンスを設定することにより、 action から Vue Router を使うことができるようになります。これによって、action 内でルーティングを行うことができます。
公式ドキュメントの解説:
https://pinia.vuejs.org/core-concepts/plugins.html#adding-new-external-properties
実装例
公式ドキュメントで省略されている箇所も含めてコード例を記載します。
main.ts
import { createApp, markRaw } from 'vue'; import { createPinia } from 'pinia'; import App from './App.vue'; import router from './router'; const app = createApp(App); const pinia = createPinia(); pinia.use(({ store }) => { store.router = markRaw(router); }); app.use(pinia); app.use(router);
ストアインスタンスのプロパティに VueRouter のインスタンスを設定しています。
action
actions: { routerPush() { this.router.push('/'); }, },
action では、ストアのインスタンスに追加されたプロパティを経由して、Vue Router を使ってルーティングすることができます。
動くWebデザインアイディア帳
ナビゲーションやモーダルなどパーツごとに動作するデモがあるので、 デザインの引き出しに使えるだけでなくてクライアントとのイメージのすり合わせにも使えそう。